.png)


In many organizations, direct database access is considered risky, noisy, and operationally expensive. Teams often need read-only access to some tables, but giving them database credentials means:
-Risk of accidental heavy queries
-Security concerns around credentials
-Lack of visibility into what is being queried
-Compliance and audit complexity
-Performance impact on production databases
So instead of exposing RDS directly, we built a fully automated export pipeline that moves selected MySQL tables from RDS → S3 and makes them queryable via Amazon Athena using AWS Glue. Everything is provisioned with Terraform, and the whole process runs securely using IAM authentication, private networking, and least-privileged policies.
This article breaks down how the pipeline works and walks through key parts of the Terraform and Python code.
In short:
1️⃣ Select list of database tables
2️⃣ Connect to RDS using IAM auth (no passwords stored)
3️⃣ Export tables as parquet
4️⃣ Upload to S3 with structured prefixing
5️⃣ Run AWS Glue Crawler
6️⃣ Automatically create / update Glue Catalog tables
7️⃣ Query everything via Athena 🎉
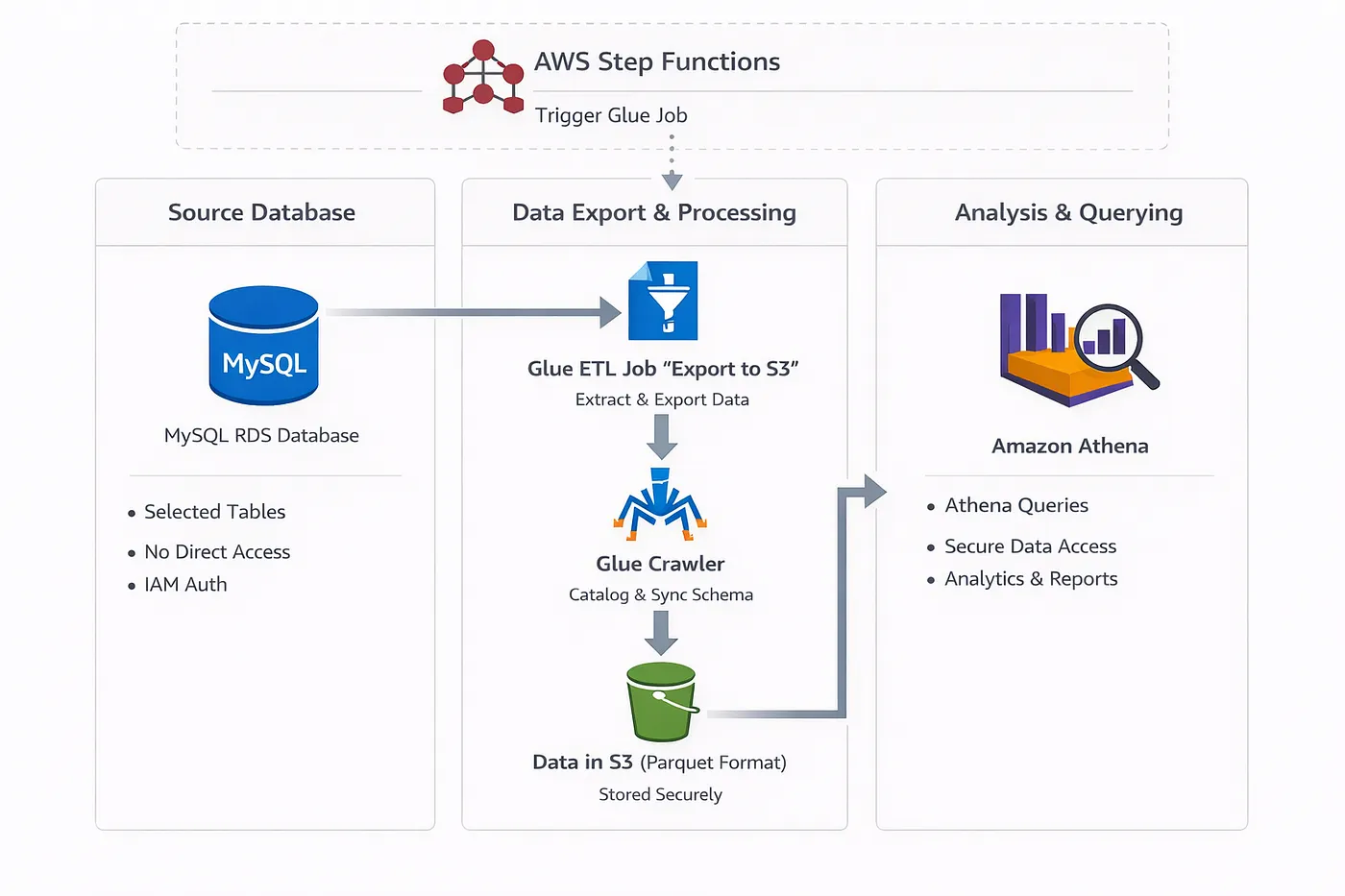
This provides:
This code is prepared to work for multi-account AWS architecture
main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
}
provider "aws" {
region = var.aws_region
}
module "db-export" {
source = "./modules/db-export"
account_id = local.account_id
aws_region = var.aws_region
environment = var.environment
vpc_id = local.vpc_id
subnet_ids = local.private_subnets
db_host = local.rds_proxy_host
db_user = "reader"
db_port = "3306"
table_names = var.table_names
crawler_name = "db-export"
rds_proxy_sg_id = local.rds_proxy_sg_id
bucket_id = local.data_platform_bucket_id
bucket_arn = local.data_platform_bucket_arn
glue_worker_type = var.glue_worker_type
}
./modules/db-export/main.tf
locals {
db_names = distinct([for table_name in var.table_names : split(".", table_name)[0]])
}
data "aws_caller_identity" "current" {}
data "aws_db_instance" "rds" {
db_instance_identifier = "${var.environment}-vault"
}
data "aws_subnet" "rds" {
for_each = toset(var.subnet_ids)
id = each.value
}
# Upload the script automatically to S3
resource "aws_s3_object" "this" {
bucket = var.bucket_id
key = "db-export/scripts/db-export.py"
source = "${path.module}/db-export.py"
etag = filemd5("${path.module}/db-export.py")
}
data "aws_iam_policy_document" "glue_assume_role" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["glue.amazonaws.com"]
}
}
}
resource "aws_iam_role" "this" {
name = "db-export-glue-role"
assume_role_policy = data.aws_iam_policy_document.glue_assume_role.json
}
resource "aws_iam_role_policy" "glue_s3_access" {
name = "db-export-glue-s3-access"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.glue_s3_access.json
}
data "aws_iam_policy_document" "glue_s3_access" {
statement {
effect = "Allow"
actions = [
"s3:PutObject",
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucket",
"s3:DeleteObject"
]
resources = [
"arn:aws:s3:::${var.bucket_id}",
"arn:aws:s3:::${var.bucket_id}/*"
]
}
}
resource "aws_iam_role_policy" "glue_rds_access" {
name = "db-export-glue-rds-access"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.glue_rds_access.json
}
data "aws_iam_policy_document" "glue_rds_access" {
statement {
effect = "Allow"
actions = [
"rds-db:connect",
"rds:DescribeDBProxies"
]
resources = [
"arn:aws:rds-db:${var.aws_region}:${data.aws_caller_identity.current.account_id}:dbuser:*/${var.db_user}",
"arn:aws:rds:${var.aws_region}:${data.aws_caller_identity.current.account_id}:db-proxy:*"
]
}
}
resource "aws_iam_role_policy" "glue_get_connection" {
name = "db-export-glue-get-connection"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.glue_get_connection.json
}
data "aws_iam_policy_document" "glue_get_connection" {
statement {
effect = "Allow"
actions = [
"glue:GetConnection",
"glue:GetConnections"
]
resources = [
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:catalog",
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:connection/*"
]
}
}
resource "aws_iam_role_policy" "glue_vpc" {
name = "db-export-glue-vpc"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.glue_vpc.json
}
data "aws_iam_policy_document" "glue_vpc" {
statement {
effect = "Allow"
actions = [
"ec2:CreateNetworkInterface",
"ec2:DescribeNetworkInterfaces",
"ec2:DeleteNetworkInterface",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeVpcAttribute",
"ec2:DescribeVpcs",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeRouteTables",
"ec2:CreateTags"
]
resources = ["*"]
}
}
resource "aws_iam_role_policy" "glue_logging" {
name = "db-export-glue-logging"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.glue_logging.json
}
data "aws_iam_policy_document" "glue_logging" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"cloudwatch:PutMetricData"
]
resources = ["*"]
}
}
resource "aws_glue_job" "this" {
name = "db-export"
role_arn = aws_iam_role.this.arn
glue_version = "5.0"
worker_type = var.glue_worker_type
connections = [for connection in aws_glue_connection.this : connection.name]
command {
script_location = "s3://${var.bucket_id}/${aws_s3_object.this.key}"
python_version = "3"
}
default_arguments = {
"--aws_region" = var.aws_region
"--db_host" = var.db_host
"--db_user" = var.db_user
"--db_port" = var.db_port
"--export_path" = "s3://${var.bucket_id}/db-export/analytics"
"--table_names" = jsonencode(var.table_names)
"--crawler_name" = var.crawler_name
"--additional-python-modules" = "pymysql,boto3"
"--enable-metrics" = "true"
"--enable-continuous-cloudwatch-log" = "true"
"--enable-continuous-log-filter" = "true"
}
depends_on = [aws_glue_connection.this]
}
resource "aws_glue_connection" "this" {
for_each = toset(local.db_names)
name = each.value
connection_properties = {
JDBC_CONNECTION_URL = "jdbc:mysql://${var.db_host}:${var.db_port}/${each.value}"
USERNAME = "reader"
PASSWORD = "" # this will be overridden with IAM auth token by python script
}
physical_connection_requirements {
availability_zone = data.aws_db_instance.rds.availability_zone
security_group_id_list = [aws_security_group.this.id]
subnet_id = [for s in data.aws_subnet.rds : s.id if s.availability_zone == data.aws_db_instance.rds.availability_zone][0]
}
}
resource "aws_security_group" "this" {
name = "db-export-glue-job-sg"
description = "Security group for Glue job"
vpc_id = var.vpc_id
}
resource "aws_security_group_rule" "glue_egress" {
type = "egress"
from_port = 0
to_port = 0
protocol = "-1"
security_group_id = aws_security_group.this.id
cidr_blocks = ["0.0.0.0/0"]
}
resource "aws_security_group_rule" "glue_self_ingress" {
type = "ingress"
from_port = 0
to_port = 65535
protocol = "-1"
security_group_id = aws_security_group.this.id
source_security_group_id = aws_security_group.this.id
}
resource "aws_security_group_rule" "glue_to_rds" {
type = "ingress"
from_port = 3306
to_port = 3306
protocol = "tcp"
security_group_id = var.rds_proxy_sg_id
source_security_group_id = aws_security_group.this.id
}
./modules/db-export/crawler.tf
resource "aws_glue_catalog_database" "this" {
name = "db-export"
description = "Glue database for tables exported from MySQL to S3"
}
resource "aws_glue_crawler" "this" {
name = "db-export"
role = aws_iam_role.this.arn
database_name = aws_glue_catalog_database.this.name
dynamic "s3_target" {
for_each = var.table_names
content {
path = "s3://${var.bucket_id}/db-export/analytics/${split(".", s3_target.value)[0]}/${split(".", s3_target.value)[1]}/"
}
}
configuration = jsonencode({
Version = 1.0
CrawlerOutput = {
Tables = {
AddOrUpdateBehavior = "MergeNewColumns" # Update schema for new columns
}
}
})
}
resource "aws_iam_role_policy" "crawler" {
name = "db-export-glue-crawler"
role = aws_iam_role.this.id
policy = data.aws_iam_policy_document.crawler_permissions.json
}
data "aws_iam_policy_document" "crawler_permissions" {
statement {
effect = "Allow"
actions = [
"glue:GetDatabase",
"glue:GetDatabases",
"glue:CreateDatabase",
"glue:GetTable",
"glue:CreateTable",
"glue:UpdateTable",
"glue:DeleteTable",
"glue:GetPartition",
"glue:CreatePartition",
"glue:UpdatePartition",
"glue:DeletePartition",
"glue:BatchGetPartition",
"glue:BatchCreatePartition"
]
resources = [
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:catalog",
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:database/${aws_glue_catalog_database.this.name}",
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:table/${aws_glue_catalog_database.this.name}/*",
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:partition/${aws_glue_catalog_database.this.name}/*",
]
}
statement {
sid = "GlueCrawlerAccess"
effect = "Allow"
actions = [
"glue:StartCrawler",
"glue:GetCrawler",
"glue:GetCrawlers"
]
resources = [
"arn:aws:glue:${var.aws_region}:${data.aws_caller_identity.current.account_id}:crawler/db-export"
]
}
}
./modules/db-export/athena.tf
resource "aws_athena_workgroup" "this" {
name = "db-export"
description = "Athena workgroup for exported data"
state = "ENABLED"
configuration {
# Enforce workgroup configuration to ensure consistent query behavior
enforce_workgroup_configuration = true
# Query result configuration
result_configuration {
# Store query results in the same bucket with dedicated prefix
output_location = "s3://${aws_s3_bucket.this.id}/"
}
# Query execution limits for cost control
bytes_scanned_cutoff_per_query = 10737418240 # 10 GB limit per query
# Engine version configuration for consistent Athena behavior
engine_version {
selected_engine_version = "AUTO"
}
}
}
resource "aws_s3_bucket_public_access_block" "this" {
bucket = aws_s3_bucket.this.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
resource "aws_s3_bucket_ownership_controls" "this" {
bucket = aws_s3_bucket.this.id
rule {
object_ownership = "BucketOwnerEnforced"
}
}
resource "aws_s3_bucket_server_side_encryption_configuration" "this" {
bucket = aws_s3_bucket.this.bucket
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
resource "aws_s3_bucket_lifecycle_configuration" "this" {
bucket = aws_s3_bucket.this.id
rule {
id = "ExpireAnalyticsDeviceEventsData"
status = "Enabled"
expiration {
days = 5
}
filter {
prefix = ""
}
}
}
./modules/db-export/variables.tf
variable "account_id" {
}
variable "aws_region" {
type = string
}
variable "environment" {
type = string
}
variable "vpc_id" {
type = string
}
variable "subnet_ids" {
type = list(string)
}
variable "db_host" {
type = string
}
variable "db_user" {
type = string
}
variable "db_port" {
type = string
}
variable "table_names" {
type = list(string)
}
variable "crawler_name" {
type = string
}
variable "rds_proxy_sg_id" {
type = string
}
variable "bucket_id" {
type = string
}
variable "bucket_arn" {
type = string
}
variable "glue_worker_type" {
type = string
default = "G.1X"
}
After provisioning the infrastructure with Terraform, the actual data movement and transformation is handled by an AWS Glue Job written in Python. This script is responsible for securely connecting to the source database, exporting selected tables, storing them in S3 as Parquet files, and finally updating the Glue Data Catalog so the data becomes queryable via Athena.
The export script as below ./modules/db-export/db-export.py
import sys
import boto3
import pymysql
import logging
import pandas as pd
import os
import json
import time
from awsglue.utils import getResolvedOptions
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
args = getResolvedOptions(
sys.argv,
["db_host", "db_port", "db_user", "table_names", "export_path", "aws_region", "crawler_name"]
)
DB_HOST = args["db_host"]
DB_PORT = int(args["db_port"])
DB_USER = args["db_user"]
EXPORT_PATH = args["export_path"]
AWS_REGION = args["aws_region"]
TABLE_NAMES = json.loads(args["table_names"])
CRAWLER_NAME = args["crawler_name"]
CRAWLER_MAX_ATTEMPTS = 30
def main():
s3_client = boto3.client("s3")
for table_name in TABLE_NAMES:
try:
db_name = table_name.split(".", 1)[0]
logger.info(f"Connecting to database: {db_name}")
token = get_iam_token()
connection = pymysql.connect(
host=DB_HOST,
user=DB_USER,
password=token,
database=db_name,
port=DB_PORT,
connect_timeout=10,
ssl={"check_hostname": False, "verify_mode": "required"}
)
export_table(table_name, connection, s3_client)
except Exception as e:
logger.error(f"Error exporting {table_name}: {str(e)}")
finally:
connection.close()
def get_iam_token():
iam_auth_session = boto3.Session()
client = iam_auth_session.client("rds", region_name=AWS_REGION)
logger.debug("Generating IAM token for DB connection...")
return client.generate_db_auth_token(
DBHostname=DB_HOST,
Port=DB_PORT,
DBUsername=DB_USER,
)
def export_table(table_name, connection, s3_client):
logger.info(f"Starting export for table: {table_name}")
cursor = connection.cursor()
query = f"SELECT * FROM {table_name}"
cursor.execute(query)
rows = cursor.fetchall()
columns = [desc[0] for desc in cursor.description]
# Create DataFrame
df = pd.DataFrame(rows, columns=columns)
# Create Parquet file locally
local_file = f"/tmp/{table_name.replace('.', '_')}.parquet"
df.to_parquet(
local_file,
engine="pyarrow",
compression="snappy",
index=False
)
# Split bucket and prefix from EXPORT_PATH
path = EXPORT_PATH.replace("s3://", "")
parts = path.split("/", 1)
bucket = parts[0]
prefix = parts[1]
# s3 key (Hive-style path)
s3_key = f"{prefix}/{table_name.replace('.', '/')}/{table_name.split('.', 1)[1]}.parquet"
# Upload to S3
s3_client.upload_file(local_file, bucket, s3_key)
logger.info(f"Export finished for table {table_name}, uploaded to s3://{bucket}/{s3_key}")
os.remove(local_file)
def run_crawler(crawler_name, region):
glue = boto3.client("glue", region_name=region)
logger.info(f"Starting Glue crawler: {crawler_name}")
glue.start_crawler(Name=crawler_name)
was_running = False
for attempt in range(CRAWLER_MAX_ATTEMPTS):
crawler = glue.get_crawler(Name=crawler_name)["Crawler"]
state = crawler["State"]
logger.info(f"Crawler state: {state} {attempt + 1}/{CRAWLER_MAX_ATTEMPTS}")
if state == "RUNNING":
was_running = True
if was_running and state == "READY":
last_crawl = crawler.get("LastCrawl")
if last_crawl:
status = last_crawl.get("Status", "UNKNOWN")
if status == "SUCCEEDED":
logger.info(f"Crawler {crawler_name} completed successfully.")
return
else:
logger.error(f"Crawler {crawler_name} failed with status: {status}")
raise RuntimeError(f"Crawler {crawler_name} failed. Status: {status}")
else:
logger.info(f"Crawler {crawler_name} completed (no LastCrawl info).")
return
logger.info(f"Crawler state: {state}. Waiting 30 seconds...({attempt + 1}/{CRAWLER_MAX_ATTEMPTS})")
time.sleep(30)
raise TimeoutError(f"Crawler {crawler_name} did not finish in time.")
if __name__ == "__main__":
main()
run_crawler(CRAWLER_NAME, AWS_REGION)When this Glue job completes:
Overall, this approach enables secure, scalable data sharing while keeping operational systems isolated and governance fully under control.
.svg)
.svg)

.svg)
.svg)
.svg)
.svg)






.svg)
.svg)



